0
我需要从使用NLTK的原始文本中获取句子依赖关系。 据我所知,斯坦福分析器允许我们创建树,但是如何从这棵树的句子中获得依赖关系,我没有发现(也许这可能,也许不是) 所以我开始使用MaltParser。下面是我使用的是和平代码:NLTK从原始文本中获取依赖关系
import os
from nltk.parse.stanford import StanfordParser
from nltk.tokenize import sent_tokenize
from nltk.parse.dependencygraph import DependencyGraph
from nltk.parse.malt import MaltParser
os.environ['JAVAHOME'] = r"C:\Program Files (x86)\Java\jre1.8.0_45\bin\java.exe"
os.environ['MALT_PARSER'] = r"C:\maltparser-1.8.1"
maltParser = MaltParser(r"C:\maltparser-1.8.1\engmalt.poly-1.7.mco")
class Parser(object):
@staticmethod
def Parse (text):
rawSentences = sent_tokenize(text)
treeSentencesStanford = stanfordParser.raw_parse_sents(rawSentences)
a=maltParser.raw_parse(rawSentences[0])
但最后一行抛出异常“‘海峡’对象有没有属性‘标签’”
changing the code above like this:
rawSentences = sent_tokenize(text)
treeSentencesStanford = stanfordParser.raw_parse_sents(rawSentences)
splitedSentences = []
for sentence in rawSentences:
splitedSentence = word_tokenize(sentence)
splitedSentences.append(splitedSentence)
a=maltParser.parse_sents(splitedSentences)
抛出同样的异常。
所以,我做错了什么。 而在一般情况:我要我在正确的方式来获得依赖这样的:http://www.nltk.org/images/depgraph0.png(但我需要从代码中访问这些依赖关系)
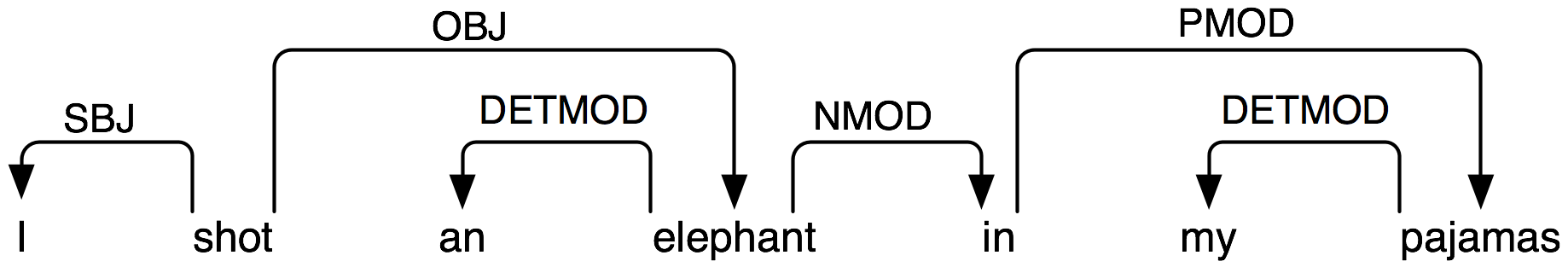{kind=link}
Traceback (most recent call last):
File "E:\Google drive\Python multi tries\Python multi tries\Parser.py", line 51, in <module>
Parser.Parse("Some random sentence. Hopefully it will be parsed.")
File "E:\Google drive\Python multi tries\Python multi tries\Parser.py", line 32, in Parse
a=maltParser.parse_sents(splitedSentences)
File "C:\Python27\lib\site-packages\nltk-3.0.1-py2.7.egg\nltk\parse\malt.py", line 113, in parse_sents
tagged_sentences = [self.tagger.tag(sentence) for sentence in sentences]
AttributeError: 'str' object has no attribute 'tag'
你可以粘贴抛出异常的轨迹吗? – lenz
当然。添加后。 – MisterMe