-1
我有两个3-D数组,其中一个包含数据,另一个包含元数据。所述元数据是日期签名,所以可以与产生的示例如下:使用类似数组中的数据过滤3D阵列
datamatrix <- array(data = c(rep(0,9), rep(0,9),(sample(0:100, 9)/1000), (sample(30:50, 9)/100), (sample(70:80,9)/100), (sample(30:50,9)/100), rep(0,9), rep(0,9)), dim = c(3,3,8))
timematrix <- array(data = c(sample(1:20), sample(30:50, 9), sample(70:90, 9), sample(110:130,9), sample(150:170,9), sample(190:210,9), sample(230:250,9), sample(260:280,9)), dim = c(3,3,8))
我希望构造充满来自第一矩阵(datamatrix)的数据的新的3D阵列和一堆NA的使得在datamatrix元件i在最终workingdata 3D阵列,像这样落入相应的日期(从相应的元数据中timematrix导出):
workingdata <- array(data = NA,
dim = c(3,3,365))
for (i in 1:length(datamatrix)){
location <- i
locationguide <- location%%9
locationfinal <- locationguide%%3
if (locationfinal == 0){
a <- 3
b <- 3
}
if (locationfinal == 1){
a <- 1
b <- 1
}
if (locationfinal == 2){
a <- 1
b <- 2
}
if (locationfinal == 3){
a <- 1
b <- 3
}
if (locationfinal == 4){
a <- 2
b <- 1
}
if (locationfinal == 5){
a <- 2
b <- 2
}
if (locationfinal == 6){
a <- 2
b <- 3
}
if (locationfinal == 7){
a <- 3
b <- 1
}
if (locationfinal == 8){
a <- 3
b <- 2
}
value <- datamatrix[i]
day <- timematrix[i]
workingdata[a,b,day] <- datamatrix[i]
}
我正在使用该数据集是千宽列的和equ长度非常长。当前的方法可以完成这项工作,但是在实际的数据中会永久使用for循环,并且由于所需的if全部都需要,所以编码会很荒谬。有没有人知道一个更好的方法来过滤这样的数据?
对于我想要的观众友好的理念,从ESRI最佳的图像概括起来: http://pro.arcgis.com/en/pro-app/tool-reference/space-time-pattern-mining/GUID-42A31756-6518-41E9-A900-2C892AF4023A-web.png
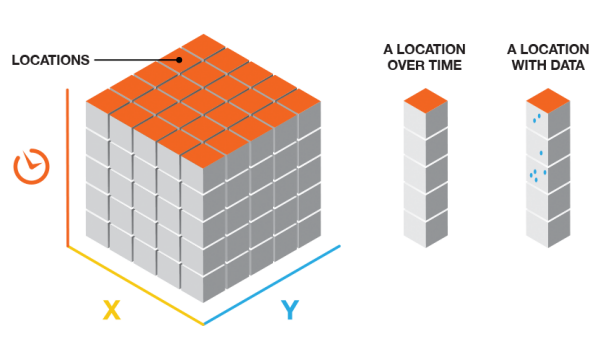{kind=link}
我每天,在观察拍摄的z维时间,一个块在z轴上落入其适当的行中,但仍保留在x和y维度的原始位置。
所以'datamatrix'和'timematrix'是数组? – Axeman
我不太确定你的'if'语句系列中的启发式。也许你可以详细说明一下? – shayaa
为什么'timematrix'中有'0'? 'workingdata'是否从第0天开始,在第1行开始? – Axeman