2
哪种模式在Linux系统上更有效?哪种更高效,Perl模式匹配还是grep?
哪种模式在Linux系统上更有效?哪种更高效,Perl模式匹配还是grep?
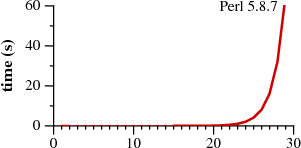
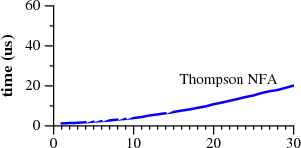
贝尔实验室的拉斯考克斯写了一个很好的文章在2007年调查中,他展示了如何使用grep
非确定性有限自动机,以提高速度超过Perl和他人。
您也可以在Perl中更改您的Regex引擎。请参阅https://metacpan.org/module/re::engine::RE2 –
非常好,但请更正术语问题:Perl正则表达式引擎不会使用DFA。事实上,如果它确实如此,它将与Thompson算法一样快地匹配Cox的正则表达式。 Perl和其他“慢”实现使用的是_backtracking_,这在技术上是一种模拟NFA的方法;这只是汤普森的一种方法。 (本质上,回溯使用状态空间的深度优先搜索,而汤普森算法使用宽度优先搜索。) –
我找到了最好的方式适合我。
之前我有一个数千个元素的数组,并grep'ped另一个数千元素的列表来从数组中获得额外的信息。
现在我把我的数组放入散列数组,然后每次都很快从数据中获取数据。
当时:
@ua1 = grep /$ip/, @ua;
目前:
$ua1[0] = $adrs{$ip};
有疑问时,[基准](http://search.cpan.org/perldoc?Benchmark)它。它完全取决于你的正则表达式和grep的样子,当然还有你的输入。 – TLP
你用它来做什么。 'if(/ foo /)'如果比使用'grep'工具的等价物快。 – ikegami
然后有'/ ...(?{...})... /'这是'grep'工具根本无法实现的。 – ikegami